2. 关系型数据库-SQL调优¶
查询的生命周期为:
- 从客户端到服务器
- 查询缓存
- 在服务器上进行解析和优化并生成执行计划
- 在存储引擎中进行查询
- 将结果返回给客户端(增量、逐步返回的过程)
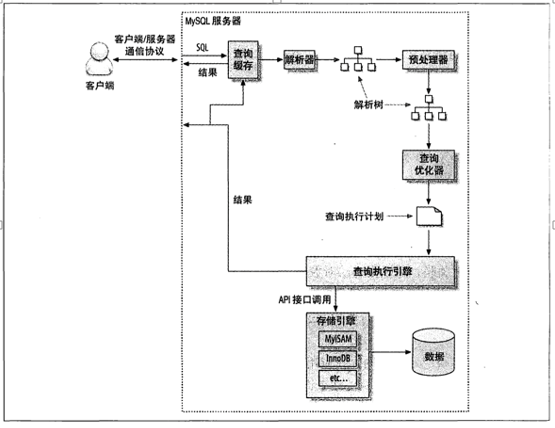
图:数据库查询处理流程(MySQL)
查询指标(记到慢日志中):响应时间(服务时间、排序时间)、扫描行数、返回行数
2.1. 获取调优信息¶
EXPLAIN是通过估计得到的结果,而SHOW STATUS则是实际的统计结果
STATUS & PROFILE¶
SHOW STATUS返回一些计数器结果(统计项首字母大写,可以结合WHERE子句)
语句:SHOW STATUS LIKE ‘%xx%’;
Handler*变量用于统计句柄操作
Handler_read_rnd_next是索引读操作的次数
Select_*变量是特定类型的 SELECT查询的计数器
Com*变量统计了每种类型的 SQL 或 CAPI 命令发起过的次数。
FLUSH STATUS; /*请空STATUS计数器*/
/*执行SQL语句*/
SHOW STATUS WHERE Variable_name LIKE 'Handler%'
OR Variable_name LIKE 'Created%'; /*获取上条SQL涉及的操作*/
SHOW PROFILE和SHOW PROFILES可用来分析当前会话中语句执行的资源消耗情况
profiling参数默认是0,需手动开启(select @@profiling;查询,set profiling=1;开启)
SHOW PROFILES; /*列出最近执行的多条语句*/
SHOW PROFILE FOR QUERY n; /*n对应SHOW PROFILES输出中的Query_ID*/
/*可以指定具体的分析项:如cpu、source*/
也可以使用INFORMATION_SCHEMA.PROFILING进行定制化的查询
例:获取某条查询各流程的执行时间和次数
SET @query_id = 1;
SELECT STATE, SUM(DURATION) AS Total_R,
ROUND(
100 * SUM(DURATION) /
(SELECT SUM(DURATION)
FROM INFORMATION_SCHEMA.PROFILING
WHERE QUERY_ID = @query_id
), 2) AS Pct_R,
COUNT(*) AS Calls,
SUM(DURATION) / COUNT(*) AS "R/Call"
FROM INFORMATION_SCHEMA.PROFILING
WHERE QUERY_ID = @query_id
GROUP BY STATE
ORDER BY Total_R DESC;
存储引擎统计信息¶
SHOW ENGINE INNODB MUTEX; 返回 InnoDB 互斥体的详细信息
每个互斥体都保护着代码中一个临界区
SHOW ENGINE INNODB STATUS; 输出InnoDB内部的计数器、统计、事务处理信息
SEMAPHORES 信号量相关信息
TRANSACTIONS 事务相关信息(包含锁的范围)
FILE I/O 显示I/O辅助线程的状态
BUFFER POOL AND MEMORY 缓冲池及内存统计信息
Buffer pool size单位是页
LATEST DETECTED DEADLOCK 当服务器内有死锁时出现
SHOW TABLE STATUS; 查询表的相关信息
例:SHOW TABLE STATUS LIKE ‘user’ G(也可查询INFORMATION_SCHEMA)
执行计划¶
Oracle中使用set autotrace on
MySQL使用EXPLAIN
5.6以前只能对SELECT语句使用,5.6后能对UPDATE、INSERT进行解释
无法获取触发器、存储过程对结果的影响
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
- select_type
- SIMPLE:简单的select(没有union和子查询)
- PRIMARY:最外面的select(在有子查询的语句中,最外面的select查询就是primary)
- DERIVED:包含在 FROM子句的子查询中的 SELECT
- SUBQUERY:包含在 SELECT列表中的子查询中的 SELECT(不在 FROM子句中)
- UNION:union语句的第二个或者说是后面那一条执行语句
- type
- null:意味着 MySQL 能在优化阶段分解查询语旬,在执行阶段不用再访问表或者索引
- const:能对查询的某部分进行优化并将其转换成一个常量
- eq_ref:索引查找,最多只返回一条符合条件的记录
通常索引是PRIMARY KEY或UNIQUE - ref:索引查找(查找和扫描的棍合体),它返回所有匹配某个值的行
称为ref是因为索引要跟某个参考值相比较
这个参考值或者是一个常数,或者是来自多表查询前一个表里的结果值 - index_merge:表示使用了索引合并优化方法
- range:查询中使用到了范围值(有限制的索引扫描)
- index:类似all,除了只有索引树被扫描(使用索引扫描做的排序)
- all:对于每个来自于先前的表的行组合,进行完整的表扫描
从好到坏依次是:
system > const > eq_ref > ref > fulltext > ref_or_null >
index_merge > unique_subquery > index_subquery > range > index > all
key:选择使用的索引
key_len:被选中使用索引的索引键长度
ref:使用哪个列或常数与key一起从表中选择行
列出是通过常量const,还是某个表的某个字段(如果是JOIN)来过滤的
rows:显示MySQL执行查询的行数(数值越大越不好,说明没有用好索引)
- Extra:该列包含MySQL解决查询的详细信息
- Using index 只使用索引树中的信息而不需要进一步搜索读取实际的行来检索表中信息
- Using where表明会读取实际的行来进行检索
- Using temporary为了解决查询,MySQL需要创建一个临时表来容纳结果
- Using filesort使用文件排序(排序的内容比较多)
EXPLAIN PARTITION 会显示查询将访问的分区
可用来观察优化器是否执行了分区过滤(针对分区表)
EXPLAIN EXTENDED 会令服务器”逆向编译”执行计划为一个 SELECT语句
再执行SHOW WARNINGS可查重构的查询
SELECT BENCHMARK(次数, 表达式); SQL类型的表达式需用引号括起来
- 只简单地返回服务器执行表达式的时间(不涉及分析和优化的开销)
- 多次执行同样的表达式会因为系统缓存命中而影响结果
2.2. 优化手段¶
优化范围查询¶
字段设置尽量避免使用null
- MySQL会为null值添加索引
- Oracle中is null、is not null不会启用索引
以下操作符可以应用索引:<、<=、=、>、>=、BETWEEN、IN、LIKE 不以 % 或 _ 开头
以下操作符不使用索引:<>、NOT IN、LIKE % 或 _ 开头
尽量避免使用OR(可以用UNION代替)
优化MAX、MIN¶
COUNT()、MIN()、MAX()
索引和列非空,通常可以帮助MySQL优化这类表达式
例如:要找到某一列的最小/大值,只需要查询在BTree索引最左端的记录,MySQL可以直接获取索引一行记录。在优化器生成执行计划的时候就可以利用这一点,在B-Tree 索引中,优化器会将这个表达式作为一个常数对待。
如果WHERE子句没有使用到索引可能涉及全表扫描
例:
SELECT MIN(actor_id) FROM actor WHERE first_name = 'penelope';
/*优化为*/
SELECT actor_id FROM actor USE INDEX(PRIMARY) WHERE first_name = 'penelope' LIMIT 1;
优化排序和分页¶
MySQL有两种排序算法
1. 先将需要排序的字段取出,使用排序区排序后再取数据(须访问两次数据)
2. 一次性将所需的Column全部取出,排序后直接返回(即filesort)
- 查询中所有需要的列和ORDER BY的列总大小超过max_length_for_sort_data字节
- 使用了BLOB或者 TEXT(即使不在OREDR BY子句中)
MySQL有两种方式可以生成有序的结果:
1. 通过排序操作:即Order By
2. 按索引顺序扫描,使用索引来对结果做排序:
- 索引的列顺序和 ORDER BY子句的顺序完全一致
- 且所有列的排序方向都一样(倒序或正序,也可以使用常量)
对于很大的表直接使用LIMIT可能效率很低,改为使用延时关联(只查主键从而使用索引),例:
SELECT film_id, description FROM film ORDER BY title LIMIT 50, 5;
/*优化为*/
SELECT film.film_id, film.description FROM film
INNER JOIN
(SELECT film_id FROM film ORDER BY title LIMIT 50, 5) AS lim
USING(film_id);
切分查询¶
分批次删除数据代替一次全部删除
row_affected = 0
do {
row_affected = do_query(
"DELETE FROM message WHERE created < DATA_SUB(NOW(), INTERVAL 3 MONTH)
LIMIT 10000"
)
} while rows_affected > 0
优化子查询和关联查询¶
优化子查询(改成联表查询,尽可能使用索引)
分解关联查询(提高缓存利用率、减小锁竞争)
MySQL 认为任何一个查询都是一次”关联”
- 对任何关联都执行嵌套循环操作(中间通过临时表)
- 不会生成查询字节码来执行查询,而是生成查询的一棵指令树(由存储引擎完成)