1. 关系型数据库-存储引擎¶
1.1. 数据库事务¶
- ACID表示
- 原子性(atomicity)
- 一致性(consistency)
- 隔离性(isolation)
- 持久性(durability)
事务级别¶
- 脏读(dirty read):
- 事务T1更新了一行记录的内容,但是并没有提交所做的修改
- 事务T2读取更新后的行,然后T1执行回滚操作,取消了刚才所做的修改
- 现在T2所读取的行就无效了
- 不可重复读(nonrepeatable read):
- 事务T1读取一行记录,紧接着事务T2修改了T1刚才读取的那一行记录
- 然后T1又再次读取这行记录,发现与刚才读取的结果不同
- 幻像读(phantom read):
- 事务T1读取一条指定的WHERE子句所返回的结果集
- 然后事务T2新插入一行记录,这行记录恰好满足T1所使用的查询条件
- 然后T1又使用相同的查询再次对表进行检索,此时却看到了事务T2刚才插入的新行
InnoDB和XtraDB存储引擎通过MVCC解决了幻像读的问题
MVCC(Multiversion Concurrency Control)是行级锁的一个变种
- 只在REPEATABLE READ和READ COMMITTED两个隔离级别下工作
- 在很多情况下避免了加锁操作,因此开销更低
- 实现了非阻塞的读操作,写操作也只锁定必要的行
InnoDB 的MVCC是通过在每行记录后面保存两个隐藏列实现的
- 这两个列,一个保存了行的创建时间,一个保存行的过期时间(或删除时间)
- 存储的不是实际的时间值,而是系统版本号(每开始一个新事务版本号都会自动递增)
事务的隔离级别,从级别低到高依次为:
较低级别的隔离通常可以执行更高的并发,系统的开销也更低
| \ | 脏读 | 不可重复读 | 幻像读 | 备注 |
|---|---|---|---|---|
| READ UNCOMMITTED | Yes | Yes | Yes | - |
| READ COMMITTED | No | Yes | Yes | - |
| REPEATABLE READ | No | No | Yes | InnoDB默认级别 |
| SERIALIZABLE | No | No | No | 会在读取的每一行数据上都加锁 |
ORACLE数据库
支持 READ COMMITTED 和 SERIALIZABLE
不支持 READ UNCOMMITTED 和 REPEATABLE READ
事务实现相关¶
事务日志是以追加的方式实现的: 存储引擎在修改表的数据时只需要修改其内存拷贝,再把该修改行为记录到持久在硬盘上的事务日志中,而不用每次都将修改的数据本身持久到磁盘。
事务数据库系统普遍都采用了 Write Ahead Log 策略
即当事务提交时,先写重做日志再修改页
分布式XA事务让存储引擎级别的ACID 可以扩展到数据库层面
MySQL 服务器层不管理事务,事务是由下层的存储引擎实现的(事务标识是一个 64 比特的数字)
MySQL 提供了两种事务型的存储引擎:InnoDB、NDB Cluster
InnoDB 用日志把随机I/O变成顺序I/O(日志是环形方式写的)
- 一旦日志安全写到磁盘,事务就持久化了,即使变更还没写到数据文件
- 如果发生了一些意外(例如断电),InnoDB 可以重放日志并且恢复已经提交的事务
1.2. 缓存&缓冲池¶
待补充
1.3. 索引¶
索引减少了服务器需要扫描的数据量,可帮助服务器避免排序和临时表(原理是排序)
- 唯一性不好的数据不适合用索引
- 只有当索引能覆盖查询结果时才能使用索引
优点:可以提高读取性能(检索)
缺点:会降低数据的写入性能(增删改)、索引可能要占用大量的存储空间
MySQL中索引是在存储引擎层而不是服务器层实现的
数据视图dba_segments可以查看索引占用空间
唯一限制和主键限制都是通过索引实现的
仅能在索引中做最左前缀匹配的 LIKE 比较(不支持通配符开头的)
索引数据结构¶
- B Tree(B-Tree)即平衡多路查找树
- 所有叶子结点位于同一层
- B+Tree相较于B-Tree:有n棵子树的结点中含有n个关键码
- B+树是一种专门针对磁盘存储而优化的N叉排序树
树有几层就涉及几次磁盘访问
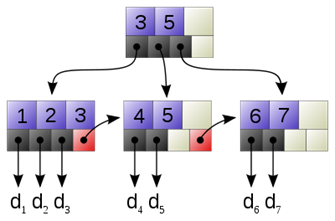
图:B+Tree数据结构
注:链接键 1-7 到数据值 d1-d7的简单例子(红色列表链接允许快速按顺序遍历)
- B-Tree 索引
MyISAM和InnoDB使用的是 B+Tree
MyISAM 使用前缀压缩来减少索引的大小(导致索引查找和倒序扫描比较慢)
- 主索引:
- MyISAM索引和数据是分开的(叶节点的data域存放的是数据记录的地址)
- InnoDB数据文件本身就是索引文件(叶节点data域保存了完整的数据记录)
- 辅助索引:
- MyISAM主索引要求key唯一,辅助索引key可以重复
- InnoDB辅助索引data域存储相应记录的主键值而不是地址
- 限制:
- 不能跳过索引中的列
- 不能打乱列的顺序
- 如果查询中有某个列的范围查询,则其右边所有列都无法使用索引优化查找
- HASH索引通过哈希表实现
- 只有精确匹配索引所有列的查询才有效(不支持范围查询,无法用于排序)
- Memory引擎默认使用此索引(速度非常快)
使用场景:提高URL等长字符串的查询效率,可建一哈希列(插入数据时配合触发器)
其他索引:空间数据索引(R-Tree)需要使用GIS相关函数进行、全文索引
数据库索引(MySQL)¶
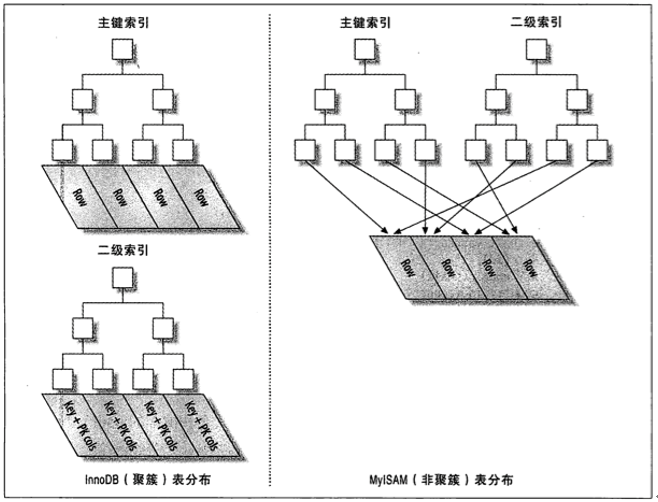
图:聚簇索引与非聚簇索引(MySQL)
聚簇索引 的顺序就是数据的物理存储顺序(一个表最多只能有一个聚簇索引)
默认使用主键建立,如果没定义主键会使用一个非空索引
若表中无数据需要聚集,可使用一个和应用无关的自增序列保证数据的按序写入
对于非自增ID做主键的表,插入新行时可能导致页分裂(大量的数据移动)
非聚簇索引 的索引顺序与数据物理排列顺序无关
InnoDB二级索引(除聚簇索引外的)的叶子节点中存储的不是”行指针”,而是主键值
索引 可以包含一个或多个列的值
当不考虑排序和分组时,将选择性最高的列放在前面通常是很好的
- 5.6之前不能跳过索引中的列(MySQL只能高效地使用索引的最左前缀列)
- 为了不跳过某索引列,可以通过IN匹配某条件的所有数据来使用索引(不能滥用)
- 5.6加入了ICP(Index Condition Pushdown)索引条件下推
原理:WHERE条件如何使用索引的判断从Server层下推到存储引擎层
功能:从而可以跳过索引中的列、为范围查询右边的列使用索引
- 条件:
- 带有WHERE子句,非子查询,非针对多表的UPDATE/DELETE操作
- 存储引擎支持ICP,且系统参数index_condition_pushdown打开(默认开)
- 索引不是聚集索引(InnoDB主键便是聚簇索引),聚簇索引本身也不需要
限制:不支持分区表(5.7解决了此问题)
索引扫描模式¶
紧凑索引扫描(Extra:Using index)
松散索引扫描(Extra:Using index for group-by)
相当于Oracle中的跳跃索引扫描(Skip Index Scan)
即不需要连续扫描索引中得每一个元组,扫描时仅考虑索引中的一部分当MySQL在GROUP BY时发现不能满足紧凑扫描时,会尝试松散扫描
如果松散扫描也不能用,那么可能会用到临时表或者文件排序
- 条件
- 查询在单一表上(5.5后可以在查询中没有GROUP BY和DISTINCT条件)
- GROUP BY指定的所有列是索引的一个最左前缀,并且没有其它的列
- 聚合函数只能使用MIN()和MAX(),并且指定的是同一列
还支持AVG()、SUM()、COUNT()- 如果查询中存在GROUP BY指定列外的索引其他部分,必须以常量形式出现
- 索引中的列必须索引整个数据列的值,而不是一个前缀索引(LIKE)