1. 基础知识-分布式通信¶
1.1. 序列化与RPC¶
序列化与RPC:网络中位于不同机器上进程间的交互
- 直接使用JSON或XML作为数据通信格式(必须反复传输相同的数据Schema信息)
- 使用二进制数据格式通信:Protocol Buffer、Thrift、Avro
序列化框架:Thrift、Avro、Protobuf、Hessian、Kryo、msgpack
- 1)PB(Google)序列化与RPC框架,开源部分未提供RPC实现,常用于数据序列化
- 官方版本支持语言:C++、Java、Python、JavaScript
相比JSON、XML、Thrift,压缩效率最高
应用:ActiveMQ用于消息存取 - 2)Thrift(FaceBook开源)序列化与RPC框架
- 支持十几种常见语言
支持List、Set、Map等数据结构(PB不支持)
应用:Hadoop、HBase、Cassandra、Hypertable、Scribe - 3)Avro(Apache开源)序列化与RPC框架(数据可采用二进制或JSON格式)
- 支持C++、Java、Python、JavaScript等6种编程语言API
使用JSON作为IDL定义语言,支持Record、Array、Map等数据结构
应用:Hadoop - Protocol Buffer、Thrift、Avro使用流程:
- 使用IDL定义消息体及RPC函数调用接口(编程语言无关)
- 使用工具依据IDL生成指定语言的编码,例:thrift –gen java MyProject.thrift
- 在应用程序中链接上一步生成的代码
Protocol buffer¶
- 使用流程
- 定义消息格式文件,通常以proto 作为扩展名;
- 使用Protocol Buffers 编译器生成特定语言(支持 C++、Java、Python)的代码文件;
- 使用Protocol Buffers 库提供的API 来编写应用程序。
消息文件格式:限定修饰符① | 数据类型② | 字段名称③ | = | 字段编码值④ | [字段默认值⑤]
①.限定修饰符包含 required、optional、repeated
- required:表示字段必须提供,不能为空,否则message会被认为是未初始化的
- optional:可选字段,可以设置也可以不设置
- 如果没有设置,会设置一个缺省值
- 可以指定一个缺省值,否则使用系统的缺省值:
数字类型缺省为0;字符类型缺省为空串;逻辑类型缺省为false
对于嵌入的message,缺省值通常是message的实例或原型- 为了兼容老的版本,升级时很多接口都把后添加的字段统一设置为optional
- repeated:字段可以被重复(包括0),可等同于动态数组或列表,值列表是按序存储的
④.字段编码值
其中1~15的编码时间和空间效率都是最高的
编码值越大,其编码的时间和空间效率就越低(相对于1-15)
生成jar包:protoc -I=$SRC_DIR –java_out=$DST_DIR $SRC_DIR/addressbook.proto
例:protoc –java_out=./src ./proto/addressbook.proto
1.2. 消息队列¶
消息队列:子系统间消息的可靠传递
ActiveMQ| RabbitMQ重量级系统、ZeroMQ轻量级、Redis轻量级(支持MQ功能)
性能:ZeroMQ > Kafka > RabbitMQ > ActiveMQ
消息持久化存储:除了ZeroMQ都支持
支持两种模式的队列:消息队列模式、Pub-Sub模式
- 消息队列模式生产者将消息存入队列、消费者从队列消费消息
- Pub-Sub模式:生产者将消息发送到指定主题队列,消费者订阅指定主题队列
生产者Push:Scribe、Flume
消费者Pull:Kafka
1)Kafka(Linkedin开源)采用Pub-Sub机制的分布式消息系统
Kafka基于磁盘读/写操作,其消息是存储在外部文件中的
最初被设计为Log收集工具,支持消息传递的”至少送达一次”语义
采用Pull的方式:即Consummer从Broker拉取应用:Linkedin的流式计算系统Samza即构建在Kafka和YARN之上
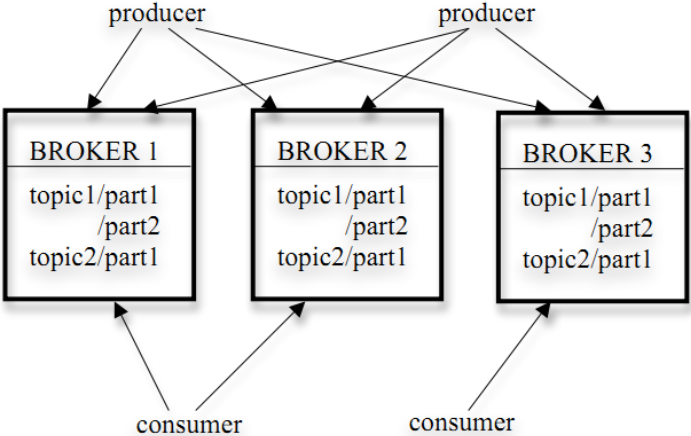
图:Kafaka构成
构成:消息生产者Producer、代理服务器Broker、消息消费者Consummer
- 其副本管理单位是Topic的数据分片(每个数据分片是有序、尾部追加的消息队列)
- 一个Topic的多个分区分布在Kafka集群的多个Server上
Server负责分区中消息的读写操作,每个分区都有一个Server为Leader状态- Kafaka的很多管理信息都放在ZooKeeper中
- 采用ISR(In-Sync Replicas)机制保证数据一致性
并未使用ZAB/Paxos:因为2f+1个副本最多允许f个副本故障
数据总线¶
数据总线的作用是能够形成数据变化通知通道:近实时性、数据回溯能力、主题订阅能力
实现模式:应用双写(潜在的数据不一致)、Log日志挖掘
Kafka也可以实现数据总线,不过其基于磁盘效率略低
Databus(Linkedin开源)数据总线系统(基于内存、客户端通过Pull方式获取数据)
Bootstrap更新数据的长期存储地(存储增量更新、数据快照)
内存数据中继器Relay(环状的内存缓冲区)短期数据存储地
Wormhole(Facebook)数据总线系统采用了Pub-Sub架构
1.3. 应用层多播通信¶
Gossip协议(即感染协议)
- 更新模型:
- 全部通知:某个节点有更新消息则立即通知所有其他节点
- 反熵:交换信息的效率Push-Pull > Pull > Push
节点P随机选择集群中另一个节点Q交换信息
Q如果更新,则类似P一样继续传播
经过一定轮数的信息交换 - 散布谣言:在反熵模型的基础上增加了传播停止判断
- 应用:
- Dynamo、Cssandra、Riak系统使用其来进行故障检测、集群资源管理、副本数据修复
BitTorrent、S3用其在节点间交换信息